3. Propositions and Inference
Una proposizione è un enunciato espresso in linguaggio formale che può essere vero o falso in un certo mondo, ed è costruito mediante simboli e connettivi logici.
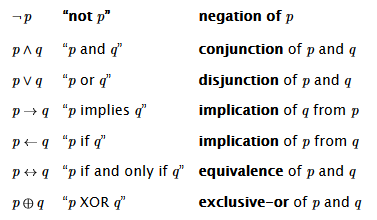
La semantica definisce il significato delle proposizioni, ovvero la corrispondenza tra simboli e stato del mondo rappresentato, le proposizioni sono interpretabili come vere o false, quelle vere determinano il mondo conosciuto dal sistema.
Un’interpretazione è una funzione \pi: atomi \rightarrow (vero, falso). Se \pi(a) = True, allora a è vero nell’interpretazione, falso altrimenti.
La verità di una proposizione dipende solo dall’interpretazione dei suoi atomi, le proposizioni potrebbero infatti avere diversi valori di verità in diverse interpretazioni.
Una knowledge base è un insieme di proposizioni dette assiomi (quindi assunte sempre come vere), e si intende una knowledge base vera se tutti i suoi assiomi sono veri. Gli assiomi servono a specificare il mondo da rappresentare attraverso la sua interpretazione intesa, ovvero quella nella mente dell’esperto di dominio, che viene formalizzata dall’ingegnere della conoscenza in assiomi.
Un modello di una KB è un’interpretazione in cui tutti gli assiomi della KB sono veri. Data KB knowledge base e g una proposizione, g è conseguenza logica di KB se e solo se g è vera in ogni modello di KB, pertanto non esistono modelli di KB nei quali g sia falsa.
Un sistema non ha accesso all’interpretazione intesa, ma conosce solo l’interpretazione data da KB. Se g è conseguenza logica di KB, allora g è vera per ogni modello di KB. Se però g non è conseguenza logica di KB allora non può trarre delle conclusioni, poichè g potrebbe essere falsa proprio nell’interpretazione intesa, ma il sistema, non conoscendola, non può stabilirlo.
1 Vincoli proposizionali
La classe dei problemi SAT (propositional satisfiability) sono caratterizzati da:
Variabili booleane (X = true oppure x, X = false oppure \neg \textit{x})
Clausole, ovvero espressioni logiche della forma l_1 \lor l_2 \lor … \lor l_k, dove ogni l_i è un letterale, cioè un atomo a o la sua negazione \neg \textit{a}. Una clausola è vera in un’interpretazione (mondo possibile) se e solo se uno dei suoi letterali è vero nell’interpretazione.
In logica proposizionale una clausola è una formula logica in una forma ristretta (un solo letterale positivo), ogni proposizione può essere convertita in forma di clausola. Un’assegnazione totale corrisponde ad un’interpretazione.
Nei CSP una clausola è un vincolo su un insieme di variabili booleane soddisfatto se almeno uno dei suoi letterali è vero.
E’ possibile convertire un CSP in un problema SAT:
Una variabile Y del CSP con dominio (v_1, …, v_k) viene convertito in k variabili booleane chiamate variabili indicatrici, che sono vere se il corrispondente valore del dominio rappresentato è assegnato alla variabile
Vengono aggiunti i seguenti due vincoli: y_i e y_j della stessa variabile non possono essere entrambi veri e almeno un y_i deve essere vero
Per ogni vincolo del CSP si prevede una clausola per ogni assegnazione dei valori che violano il vincolo.
2 Clausole definite proposizionali
Il linguaggio delle clausole definite proposizionali è un sottolinguaggio della logica proposizionale che non ammette ambiguità o incertezza nella rappresentazione.
Le proposizioni hanno lo stesso significato che hanno nel calcolo proposizionale, ma non tutte le proposizioni sono ammesse in una KB.
La sintassi delle clausole definite proposizionali è la seguente: h \leftarrow a_1 \land a_2 \land … \land a_m (h se a_1 e … e a_m), dove h è la testa della clausola e a_1 \land … \land a_m è il corpo. Se il corpo è vuoto si parla di fatto. La clausola definita è falsa in un’interpretazione I se a_1, …, a_m sono tutte vere in I ma h è falsa in I, vera altrimenti.
Una knowledge base è un insieme di clausole definite.
2.1 Domande e risposte
Una query è un modo per chiedere se una proposizione è conseguenza logica di una knowledge base. Le query hanno la forma ask b, con b atomo o congiunzione di atomi (per KB di clausole definite). La risposta sarà yes se il corpo è conseguenza logica della knowledge base, no se il corpo non è conseguenza logica, ovvero è impossibile determinare la verità con la conoscenza disponibile, non significa che b sia falso nell’interpretazione intesa.
3 Dimostrazioni
Data una procedura di dimostrazione, KB \vdash g indica che si può produrre una prova del fatto che g può essere derivata da KB.
Una procedura di dimostrazione è corretta se ogni proposizione dimostrata dalla procedura è conseguenza logica di KB, ovvero se KB \vdash g, allora g conseguenza logica di KB (KB \models g).
Una procedura di dimostrazione è completa se ogni conseguenza logica della KB può essere dimostrata dalla procedura, ovvero se KB \models g, allora KB \vdash g.
3.1 Procedura bottom-up
Lo scopo è quello di derivare tutte le conseguenze logiche di una KB, costruendo la prova gradualmente basandosi sugli atomi già dimostrati, nel senso di derivare fatti nuovi a partire da quanto è già stato provato.
L’idea generale si basa su una regola di derivazione, una forma generalizzata di una regola d’inferenza detta modus ponens: se h \leftarrow a_1 \land … \land a_m è una clausola definita nella KB, e ogni a_i è stato provato, allora h può essere derivato. Ogni fatto (m = 0) si considera già provato.
L’algoritmo è definito come segue: si mantiene una lista di atomi già provati C, e ad ogni iterata fin quando gli atomi selezionabili non terminano si seleziona un h dalla KB tale che gli atomi della conseguenza logica sono stati provati (ovvero sono stati inseriti in C), e si inserisce h in C.
3.1.1 Proprietà della procedura bottom-up
Punto fisso: l’insieme C finale è un punto fisso perchè ogni applicazione successiva delle regole di derivazione non cambiano C. Ovvero detta I l’interpretazione in cui ogni atomo in C è vero e gli altri sono falsi, I dev’essere un modello di KB ed è il modello minimale, ovvero ha il minor numero di proposizioni vere tra tutti i suoi modelli.
Correttezza: ogni atomo in C è conseguenza logica di KB.
Completezza: tutte le conseguenze logiche sono derivabili. Supponendo KB \models g, allora g è vero in ogni modello di KB, e quindi è vero anche in quello minimo, ovvero in C, quindi KB \vdash g.
3.2 Procedura top-down
Lo scopo è quello di effettuare una ricerca backward partendo da una query per determinare se questa segua logicamente dalle clausole di KB.
Questa procedura è chiamata Risoluzione SLD.
In sostanza, definiamo una clausola di risposta come yes \leftarrow a_1 \land a_2 \land … \land a_m, dove yes è un atomo speciale vero se la risposta alla query è yes.
A questo punto, data la query ask q_1 \land q_2 \land … \land q_m allora la clausola di risposta iniziale sarà yes \leftarrow q_1 \land q_2 \land … \land q_m.
L’algoritmo seleziona (don’t-care non-determinism^{1}) un atomo del corpo da dimostrare e si procede attraverso dei passi di risoluzione, per cui si sceglie una clausola definita in KB avente come testa l’atomo selezionato, e si sostituisce l’atomo della query con il corpo di questa clausola definita scelta.
L’atomo viene poi aggiunto a un set di atomi G per non essere scelto nuovamente. Se l’algoritmo ha successo sarà data una clausola di risposta con corpo vuoto. Se invece non ci sono clausole la cui testa è un atomo della query l’algoritmo fallisce.
La procedura è non deterministica perchè dovrà scegliere (don’t-know non-determinism^{1}) una clausola definita per la risoluzione della dimostrazione. Il Prolog, in alternativa a G, mantiene una lista ordinata di atomi (con duplicati), quindi non ha l’overhead di controllare i duplicati, che invece è presente se G fosse un set.
Ogni atomo di un corpo può essere selezionato, e se questo non porta a dimostrazione, altre selezioni non sono necessarie. Al momento della scelta della clausola invece l’algoritmo ha la necessità di cercare la scelta che permetta il successo della dimostrazione.
L’algoritmo induce quindi a un grafo di ricerca, dove ogni nodo è una clausola di risposta, e i vicini di yes \leftarrow a_1 \land … \land a_m, con a_1 atomo selezionato, rappresentano tutte le possibili clausole di risposta ottenute risolvendo a_1. I nodi obiettivo sono nodi del tipo yes \leftarrow. Il grafo viene generato dinamicamente, perchè altrimenti bisognerebbe anticipare qualsiasi possibile query. A questo punto si può usare qualsiasi metodo di ricerca su grafo, basta un percorso di successo affinchè la query sia conseguenza logica della KB.
La strategia di selezione dell’atomo per la risoluzione condiziona efficienza e terminazione, infatti scegliendo magari l’atomo più a sinistra sempre si rischia di incontrare dei loop.
La strategia migliore è quella di selezionare l’atomo che porti al fallimento più facilmente.
La strategia comune è quella di ordinare gli atomi utilizzando una euristica.
3.3 Procedura bottom-up vs Procedura top-down
Le dimostrazioni TD e BU sono interscambiabili, la BU è utile a provare consistenza e completezza della TD. BU prova ogni atomo una sola volta; TD potrebbe provare lo stesso atomo più volte, ma si concentra su quelli rilevanti per la query. Con la TD sono possibili cicli infiniti.

4 Interazione con l’utente
Non tutte le informazioni sono conosciute, pertanto si realizzano degli atomi askable, ossia verità acquisibili dall’utente a run-time. La procedura top-down, selezionato un atomo da dimostrare, se questo è askable e non vi è una risposta utente memorizzata chiede all’utente se sia vero o falso, altrimenti utilizza la risposta utente memorizzata.
5 Debugging a livello di conoscenza
Il knowledge-level debugging è un processo che consiste nel trovare errori nelle KB facendo riferimento solo al significato dei simboli e quanto risulta vero nel mondo codificato, senza considerare i passi di ragionamento. Gli errori non sintattici possibili possono essere i seguenti: - risposta errata, ovvero un atomo falso è stato derivato dall’interpretazione intesa - risposta mancante, ovvero una dimostrazione è fallita per un qualche atomo vero, che avrebbe dovuto avere successo - loop infinito, nei casi di utilizzo di procedure top-down, evitabile con meccanismi di cycle pruning in base alla strategia di selezione usata. Nella bottom-up non vi sono cicli.
5.1 Risposte errate
Per il debugging dei falsi positivi procediamo in questo modo: sia g l’atomo dimostrato come vero, ma falso nell’interpretazione intesa, ci sarà quindi una clausola g \leftarrow a_1 \land … \land a_k nella KB usata per provare g. A questo punto possiamo fare due ipotesi: se tutti gli atomi a_i della clausola sono veri, allora questa è errata, altrimenti, se uno o più a_i sono falsi nell’interpretazione intesa il problema va risolto ricorsivamente. Questo ci porta al seguente algoritmo:

Questo algoritmo trova una clausola errata richiedendo all’utente di rispondere a domande del tipo vero o falso.
5.2 Risposte mancanti
Un caso di falso negativo segnala il caso di clausole mancanti tra gli assiomi della KB, ovvero un atomo g, vero nel dominio, non conseguenza logica della KB. Conoscendo l’interpretazione intesa dei simboli e conoscendo quali query sarebbero vere, un esperto del dominio può debuggare una risposta mancante. Questo può essere fatto, dato l’atomo g vero non dimostrato, usando un algoritmo che restituisce un atomo per cui manchino clausole per essere dimostrato.

6 Dimostrazione per contraddizione
Si può ragionare ammettendo regole che producano contraddizioni, per specificare casi impossibili.
6.1 Clausole di Horn
Estendiamo linguaggio delle clausole definite utilizzando un atomo speciale false, falso in tutte le interpretazioni.
Un vincolo d’integrità è una clausola con false come testa: false \leftarrow a_1 \land … \land a_k, cioè se tutti gli a_i sono veri, siamo in un modello contraddittorio.
Posso quindi dimostrare cose del tipo KB \models \neg c, cosa che prima non potevo fare (conclusioni negative).
Ricorda che false \leftarrow a_1 \land … \land a_k = \neg a_1 \lor … \lor \neg a_k = \neg(a_1 \land … \land a_k): si può quindi dimostrare che congiunzioni di atomi sono false in tutti i modelli di KB, ovvero provare una disgiunzione di negazioni di atomi (conclusioni disgiuntive).
Una clausola di Horn è una clausola definita oppure un vincolo d’integrità. A differenza di una knowledge base basata solo su clausole definite, da una knowledge base basata su clausole di Horn si possono derivare negazioni di atomi tramite modus tollens, se p \rightarrow q ma \neg q nel modello, allora \neg p.
Un insieme di clausole KB è insoddisfacibile se non ha modelli (KB \models false), lo si mostra con metodi matematici.
Un insieme di clausole KB è inconsistente rispetto a una procedura di dimostrazione \vdash se consente di derivare false (KB \vdash false), quindi rispetto all’insoddisfacibilità si mostra usando una procedura di dimostrazione.
Una KB di sole clausole definite è sempre soddisfacibile, banalmente considerando l’interpretazione in cui tutti gli atomi sono veri, ciò non vale per le KB di clausole di Horn.
7 Assumibili
Un assumibile è un atomo che può essere assunto come vero in una dimostrazione per contraddizione, in modo che un sistema con una knowledge base basata su clausole di Horn e assumibili espliciti, possa provare una contraddizione estraendo le combinazioni di assunzioni che non possono essere vere. Invece di provare una query, il sistema prova a dimostrare false, e colleziona gli assumibili che ha usato nella dimostrazione.
7.1 Conflitti
Un conflitto è un set di assumibili che, data KB, implicano il falso: dati C gli assumibili KB \cup C \models false.
Un conflitto è minimale se nessun suo sottoinsieme è un conflitto.
8 Diagnosi basata sulla consistenza
Dato un set di conflitti, una diagnosi basata su consistenza è un set di assumibili che ha almeno un elemento in ogni conflitto. Una diagnosi è minimale se nessun suo sotto-insieme è una diagnosi.
9 Ricerca dei conflitti in KB di clausole di Horn
9.1 Implementazione bottom-up
Si estende l’algoritmo bottom-up per clausole definite: gli elementi dell’insieme C sono coppie (a, A), con a atomo e A set di assumibili che implicano a rispetto a KB.
C viene così inizializzato: C = {(a, {a}) | a assumibile}.
Le clausole vengono utilizzate per derivare nuove conclusioni: se c’è una clausola h \leftarrow b_1 \land … \land b_m tale che \forall b_i \exists A_i tale che (b_i, A_i) \in C, allora (h, A_1 \cup .. . \cup A_m) può essere aggiunto a C.
Per i fatti si aggiunge (h, {}).
Quando la coppia ⟨false, A⟩ è generata, gli assumibili A formano un conflitto.
9.2 Implementazione top-down
Deriva dall’omologa per clausole definite, eccetto che la query principale da provare è false, e che gli assumibili incontrati nella dimostrazione non vanno dimostrati, ma solo raccolti per essere assunti come veri, quelli che rimangono sono quelli che danno luogo a conflitto. L’algoritmo termina quando l’insieme G contiene solo assumibili, che sono quelli che formano un conflitto.
Scelte diverse di atomi (ricordare il non determinismo) possono portare a individuare conflitti diversi, in caso di mancanza di scelte, l’algoritmo fallisce.
10 Assunzione di conoscenza completa vs Assunzione di mondo aperto
L’assunzione di conoscenza completa assume che, per ogni atomo, le clausole che hanno come testa quell’atomo coprono tutti i casi per cui l’atomo è vero. Un atomo senza clausole è quindi falso. Sotto questa assunzione, l’agente può concludere che un atomo è falso se non riesce a dimostrare che sia vero.
L’assunzione di mondo aperto invece assume che l’agente non sappia tutto e quindi non può trarre conclusioni in caso di mancanza di conoscenza. In logica normalmente non si assume che una KB definisca tutta la conoscenza su un dato dominio, si lavora quindi con mondo aperto.
10.1 Completare la base di conoscenza
Dato l’atomo a e tutte le clausole della KB che lo definiscono: a \leftarrow b_1, …, a \leftarrow b_n, esse possono essere riassunte da un’unica proposizione a \leftarrow b_1 \lor … \lor b_n. Se a è vero allora, per l’assunzione di conoscenza completa, dovrà necessariamente essere vero uno dei b_i rispetto a qualunque interpretazione, quindi si può aggiungere a \rightarrow b_1 \lor … \lor b_n.
Per completare ogni atomo in una knowledge base con assunzione di mondo chiuso, ci avvaliamo del completamento di Clark che codifica la congiunzione/equivalenza delle due proposizioni: a \iff b_1 \land … \land b_n. Il completamento di Clark considera che se non ci sono regole per l’atomo a, allora a \iff false, ovvero a è falso.
10.2 NAF: Negation as failure
Un letterale è un atomo o negazione di un atomo. La definizione di clausola definita può essere estesa per permettere dei letterali nel corpo invece che semplici atomi.
Sotto assunzione di mondo completo rappresentiamo la negazione come ~a (negation as failure) per distinguerla dalla negazione classica (che non assume mondo completo).
Grazie al completamento di Clark il sistema può dimostrare delle negazioni.
Sotto NAF, il corpo g è conseguenza di KB se KB^{'} \models g, dove KB^{'} è il completamento di Clark di KB. Una negazione ~a nel corpo di una clausola diventa \neg a nel completamento.
10.2.1 Problematiche
Con la NAF, le KB non acicliche diventano problematiche.
Ad esempio, data la KB non aciclica: a \leftarrow ~b, b \leftarrow ~a, possiamo usare il completamento di Clark, avendo quindi una KB equivalente ad a \iff \neg b, ovvero a e b devono avere valori di verità opposti. Un’altra KB non aciclica può essere a \leftarrow ~a, il cui completamento è a \iff \neg a, che sarebbe logicamente inconsistente.
Il completamento di Clark di una KB aciclica è sempre consistente e prevede sempre un solo valore di verità per ogni atomo.
11 Logica monotona e non monotona
Una logica è monotona se ogni proposizione derivabile da una KB rimane derivabile dopo l’aggiunta di altre proposizioni. La logica delle clausole definite è monotona.
Una logica è non monotona se alcune conclusioni possono essere invalidate con l’aggiunta di altri assiomi.
La logica delle clausole definite + NAF è non monotona.
La logica non monotona è utile a rappresentare casi predefiniti, ad esempio una regola di default che resta valida fintantoché non si verifichi un’eccezione.
Per farlo sfrutto proprio la NAF: per asserire ad esempio che normalmente b è vera se c è vera: b \leftarrow c \land ~ ab_a, con ab_a che indica l’anormalità rispetto a qualche aspetto di a, pertanto dato c si può derivare b, a meno che non venga asserito ab_a, inibendo il comportamento di default.
12 Procedure di dimostrazione per la NAF
12.1 Bottom-up
La differenza con l’algoritmo definito per le clausole definite consiste nell’aggiungere il letterale ~p all’insieme C quando p fallisce. Il fallimento può essere definito ricorsivamente: p fallisce se fallisce il corpo di ogni clausola che abbia p come testa. Un corpo fallisce se almeno uno dei suoi letterali fallisce: b_i fallisce se derivo ~b_i, ~b_i fallisce se derivo b_i.
12.2 Top-down
L’algoritmo è analogo a quello delle clausole definite ma quando seleziona un ~a, parte una nuova dimostrazione per a, se questa fallisce ancora, allora ~a ha successo, altrimenti l’algoritmo fallisce e deve tentare altre scelte, se disponibili. Questo vale solo nel caso di fallimento finito, ovvero non ho conclusioni se l’algoritmo diverge. Ad esempio data la sola regola p \leftarrow p e la query ask p, il completamento è p \iff p, una procedura corretta non può però concludere ~p perchè non segue logicamente dal completamento.
13 Abduzione
L’abduzione è una forma di ragionamento nella quale si fanno delle ipotesi per spiegare delle osservazioni (ad esempio se si osserva che qualche luce non sta funzionando, si fanno ipotesi su quanto sta succedendo). Dato un caso osservato, si fanno ipotesi che possono implicare le osservazioni fatte, ossia ciò che, se verificato, rende le osservazioni vere senza contraddizioni (giustificherebbero qualsiasi conclusione altrimenti).
Si differenzia dalla deduzione che mira alle conseguenze logiche di un set di assiomi, e dall’induzione, che comporta l’inferenza di relazioni generali da esempi.
Data una KB con clausole di Horn, e un set di assumibili A, invece di aggiungere delle osservazioni alla KB, le osservazioni vanno spiegate.
Uno scenario (KB, A) è un subset H di A tale che KB \cup H è soddisfacibile, ovvero esiste un modello in cui tutti gli elementi di KB e di H sono veri. Questo avviene se nessun subset di H è un conflitto di KB.
Una spiegazione della proposizione g da (KB, A) è uno scenario che assieme a KB, abbia g come conseguenza: KB \cup H \models g.
Una spiegazione minimale di g da (KB, A) è una spiegazione H di g da (KB, A) tale che non c’è un subset di H che è anche spiegazione di g da (KB, A).
13.1 Diagnosi abduttiva
In una diagnosi abduttiva, l’agente ipotizza dei malfunzionamenti e delle parti funzionanti correttamente, per spiegare i sintomi osservati. Questo è differente dalla diagnosi basata su consistenza (CBD) per diversi motivi:
In CBD viene modellato solo il comportamento normale, e le ipotesi sono assunzioni di comportamento normale. Nella diagnosi abduttiva, comportamenti anomali e non vanno rappresentati, e le assunzioni vengono fatte per tutti i comportamenti
Nella diagnosi abduttiva l’osservazione va spiegata. In CBD l’osservazione viene aggiunta alla KB e si dimostra false.
13.2 Ragionamento abduttivo: procedure
13.2.1 Bottom-up
Con la bottom-up si calcolano le spiegazioni minimali per ogni atomo.
13.2.2 Top-down
Con la top-down si trovano spiegazioni di un g generando i conflitti ma dimostrando g, invece di false. Le spiegazioni minimali di g sono l’insieme minimale di assumibili raccolti nella prova.
^{1} In don’t-care non-determinism, if one selection does not lead to a solution, neither will other selections. Correctness should not be affected by the selection, but efficiency and termination may be. When there is an infinite sequence of selections, a selection mechanism is fair if a request that is repeatedly available to be selected will eventually be selected. The problem of an element being repeatedly not selected is called starvation. In don’t-know non-determinism, just because one choice did not lead to a solution does not mean that other choices will not. It is useful to think of an oracle that could specify, at each point, which choice will lead to a solution.