2 Cassandra
Cassandra is a Peer to Peer massively linearly scalable NoSQL database, fully distributed, with no single point of failure due to horizontal scaling (horizontal scaling: add commodity hardware to a cluster; vertical scaling: add RAM and CPUs to a single machine).
Cassandra is a Column-family database, which uses Cassandra Query Language (CQL) as its query language, similar to SQL but with some differences due to its NoSQL nature.
2.1 Architecture
- Node: one Cassandra instance
- Rack: a logical set of nodes
- Data Center: a logical set of racks
- Cluster: a set of nodes which map to a single complete consistent hashing ring
Nodes join a cluster based on the configuration of their own cassandra.yaml file, which contains the cluster name, the IP address of initial nodes for a new node to contact and discover the cluster topology (known as seed), and the IP address through which this particular node communicates.
A coordinator node is the node chosen by the client (so not a true coordinator) to receive a particular read or write request to its cluster. Given the peer to peer nature, any node can coordinate any request. The coordinator is essentially the transaction manager for the request, and is responsible for forwarding the request to the appropriate nodes (resource managers), collecting their responses, and returning the final result to the client.
The coordinator manages the replication factor (RF), that is, how many replicas of each object are stored in the cluster. Every write to every node is individually time-stamped.
The coordinator also applies the consistency level (CL), that is, how many replicas must acknowledge a read or write operation before it is considered successful. The CL can be set per operation, and can range from 0 (no acknowledgments required) to ALL (all replicas must acknowledge). Common CLs include ANY, ONE (one replica), QUORUM (RF/2 + 1) and ALL.
2.2 Consistency Hashing
Data is stored on nodes in partitions, each identified by a unique token. A partition is a storage location on a node, a token is an integer value generated by a hashing algorithm, identifying a partition’s location within a cluster. Any partition in a cluster is hashed, regardless of its nodes. The partitioner is the system (equal across all nodes in the cluster) which hashes tokens from partition key (= the primary key of the table) values, determining the token range for each partition. Each node is assigned a token, node tokens are the highest value in the segment owned by that node. This segment is the primary token range owned by this node. Nodes also store replicas of partitions owned by other nodes (secondary range), according to the RF.
Virtual nodes allow each physical node to own non-contiguous token ranges, each representing a separate token range on the ring, improving data distribution. This allows for more data distribution across nodes and simplifies the process of adding or removing nodes from the cluster, as data can be redistributed more granularly.
When a write request is received by a coordinator node, it uses the partitioner to hash the partition key value of the row being written, determining the token for that partition. The coordinator then identifies the node responsible for that token (the primary replica) and forwards the write request to that node. Based on the RF, the coordinator also identifies additional nodes to store replicas of the partition and forwards the write request to those nodes as well.
When a read request is received, the coordinator hashes the partition key value to determine the token and identifies the node responsible for that token. The coordinator then forwards the read request to that node and, based on the CL, may also forward the request to additional replicas.
2.3 Keyspace and replication
Replication factor is configured when a keyspace is created. A keyspace is the container for data in Cassandra, similar to a database in relational databases. It defines the replication strategy (on which node should each replica be placed) and the replication factor for its data. We can use a SimpleStrategy replication, that is, one replication factor for entire cluster, without virtual nodes, assigning nodes clockwise around the ring. Or we can use a NetworkTopologyStrategy replication, that is, different replication factors for different data centers, with virtual nodes. NetworkTopologyStrategy is the one used in production environments.
The target table’s keyspace determines replication factor and replication strategy. Given the peer to peer nature, all partitions can be considered as “replicas”: the first replica is placed on the node owning its token’s primary range, the other dependent on the replication strategy:
- SimpleStrategy: create replicas on nodes subsequent to the primary range node, clockwise around the ring
- NetworkTopologyStrategy: create replicas across racks and data centers, clockwise or using virtual nodes.
2.4 Hinted Handoff
Hinted handoff is a recovery mechanism for writes targeting offline nodes. Coordinator can store a hinted handoff if the target node for a write is known to be down or fails to acknowledge. Coordinator stores the hint and the write is replayed when the target node comes back online. In this way, if a node disappears and other nodes realize it’s missing, the workload is distributed among the remaining nodes, and when the node comes back online (modifying the responsibilities in the ring), it can catch up on missed writes without impacting overall cluster availability.
Gossip protocol is used to check if all nodes are active based on the concept of heartbeats. Each node periodically sends heartbeat messages to a subset of other nodes in the cluster, sharing information about its status and the status of other nodes it knows about. This allows nodes (and, specifically, the coordinator) to maintain an updated view of the cluster’s topology and detect node failures or recoveries.
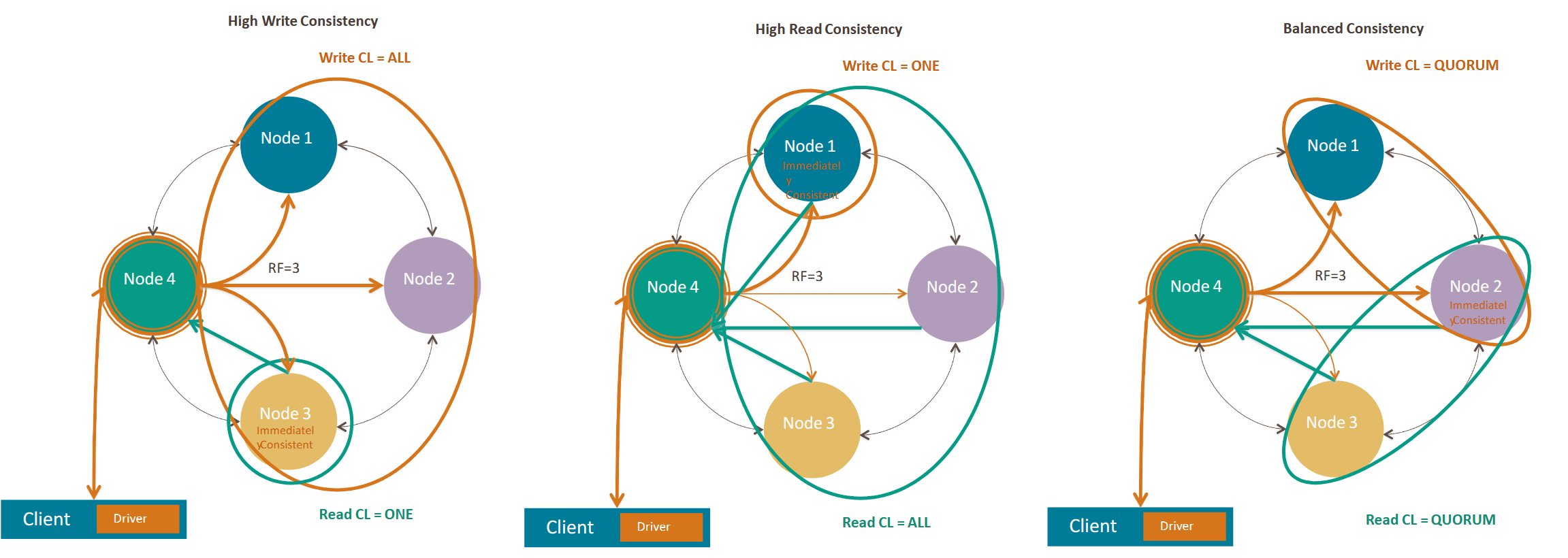
2.5 Consistency Levels
The partition key determines which nodes are sent any given request. The consistency level (CL) determines how many nodes must acknowledge a read or write operation before it is considered successful.
In write request, we want to know how many nodes must acknowledge the write before returning success to the client.
In read request, we want to know how many nodes must acknowledge by sending their most recent copy of the data.
We can use immediate consistency levels, that is, we want the most recent copy of the data, or eventual consistency levels, that is, we want the data to be eventually consistent across all replicas.
Immediate consistency, achieved by Consistency Level ALL, guarantees that all replicas have the most recent copy of the data before returning success to the client. This is the strongest consistency level, but also the slowest and least available, as it requires all replicas to be online and responsive.
Eventual consistency, achieved by Consistency Level ONE (or QUORUM), allows for some replicas to be out of date or offline, as long as a majority of replicas have the most recent copy of the data. This is a weaker consistency level, but also faster and more available, as it allows for some replicas to be offline or unresponsive.
Recalling the CAP theorem, if we want to achieve the consistency, we have to sacrifice availability in case of network partition. So, if we set CL to ALL, we achieve consistency but sacrifice availability. If we set CL to ONE or QUORUM, we achieve availability but sacrifice consistency.
If CL(read) + CL(write) > RF, we achieve immediate consistency.
- If CL(write) = ALL, we achieve immediate consistency for writes
- Example: RF = 3, CL(write) = ALL, CL(read) = ONE
- If CL(read) = ALL, we achieve immediate consistency for reads
- Example: RF = 3, CL(write) = ONE, CL(read) = ALL
- If CL(write) = QUORUM and CL(read) = QUORUM, we achieve immediate consistency for both reads and writes
- Example: RF = 3, CL(write) = QUORUM, CL(read) = QUORUM
Clock synchronization across nodes is crucial for maintaining data consistency and integrity in Cassandra. Each write operation is timestamped, and during read operations, the most recent timestamp determines the latest version of the data. If clocks are not synchronized, it can lead to scenarios where older data overwrites newer data or inconsistencies arise during read operations.
2.6 Data Model
The Cassandra data model defines:
- Column family as a way to store and organize data
- Table as a two-dimensional view of a multi-dimensional column family
- Operations on tables using the Cassandra Query Language (CQL)
Row is the smallest unit that stores related data in Cassandra. A row key uniquely identifies a row in a column family, the row stores pairs (column keys, column values), the column key uniquely identifies a column value in a row, the column value stores one value or a collection of values, or may be empty as the column key could store all the desired data.
Row key -> column key: value key
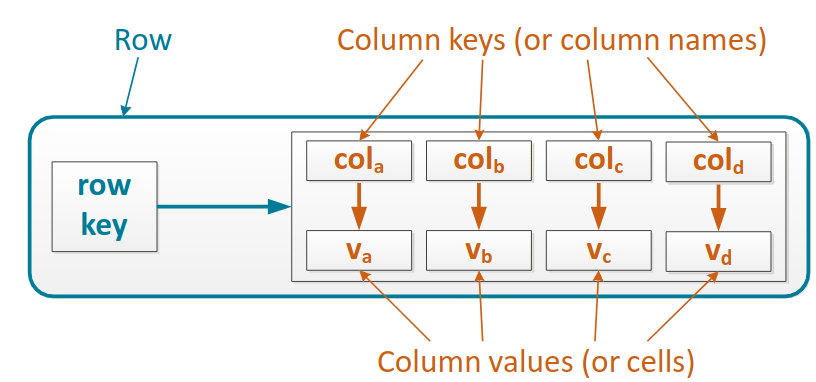
A row can be retrieved with its row key, a column value can be retrieved when we know both the row key and the column key.
Rows may be skinny or wide:
- Skinny rows: has a fixed, relatively small number of column keys
- Wide rows: has a relatively large number of column keys (hundreds or thousands); this number may increase as new data values are inserted
We can define composite row key, that are, multiple component separated by colon, or composite column key, multiple components separated by colon, they are sorted by each component.


Row can contain both simple and composite column key.

A column family is a collection of rows which keeps the same structure.
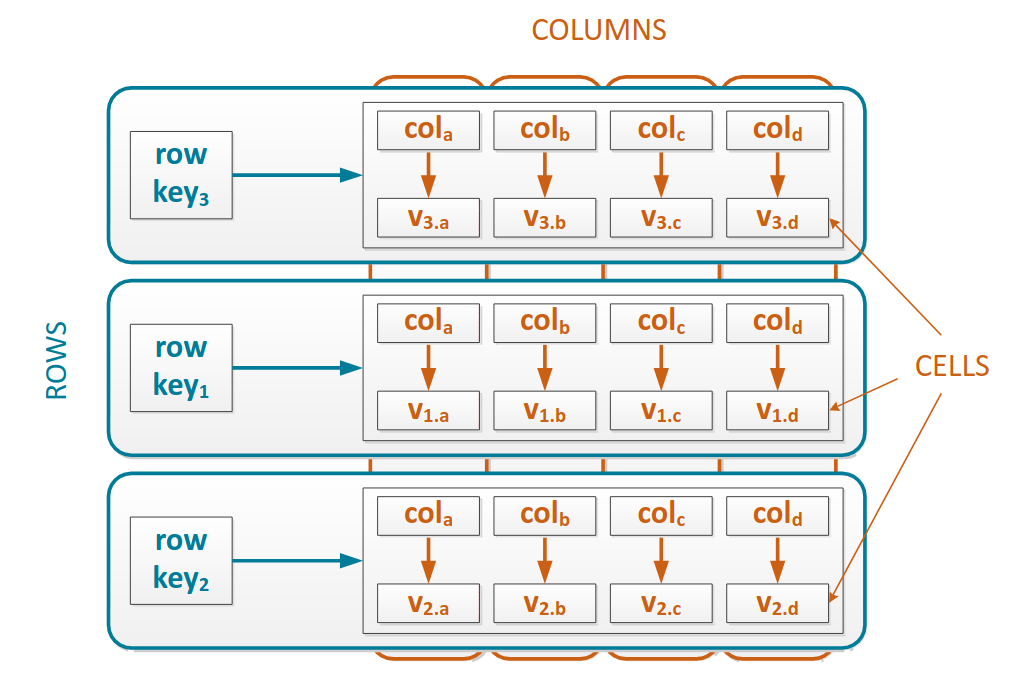
They can also be sparse, so some column keys may be missing in some rows.
To see this columns, we use the concept of table. We define a partition key, that is, the primary key of this virtual table, and the columns defined by the column keys of the column family.
The primary key of the table is composed by the partition key and the clustering columns (if present).
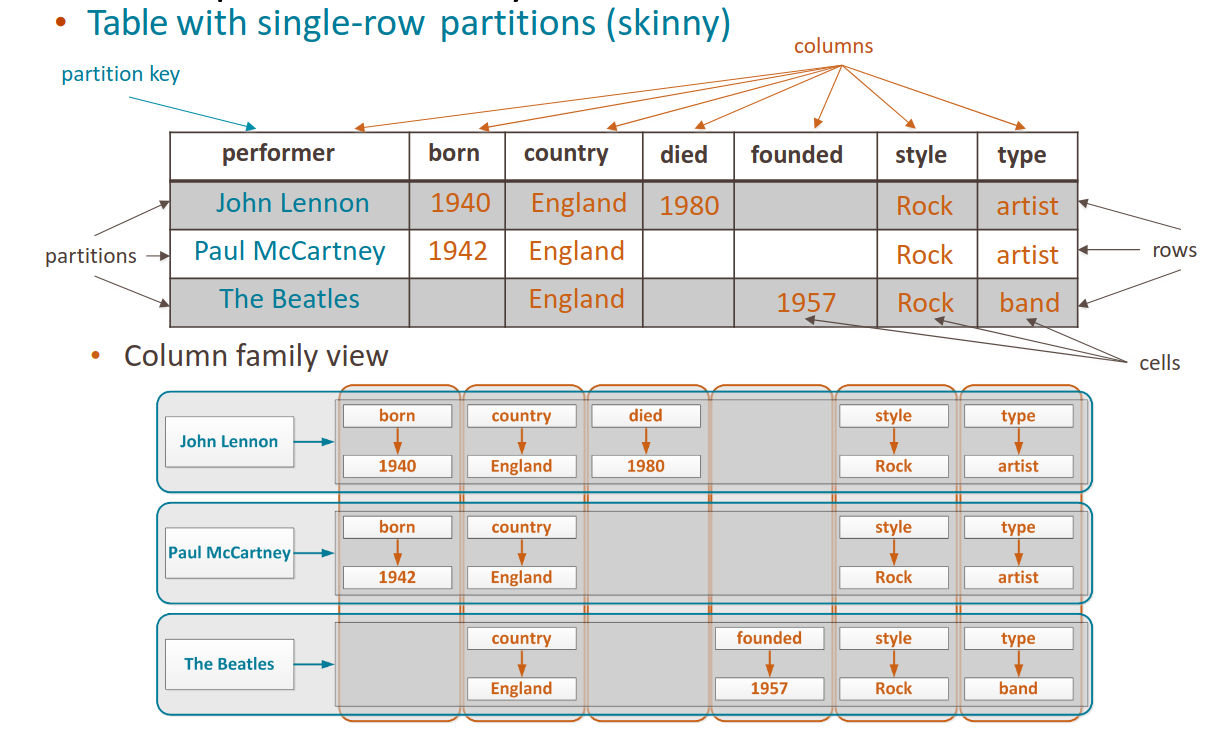
We can also have composite partition key. If we have composite column key, we have to define the clustering columns, that is, the components of the composite column key. In a skinny table we don’t have clustering columns.
We can also have static columns, shared for all rows in a partition. Static columns cannot be part of a primary key.
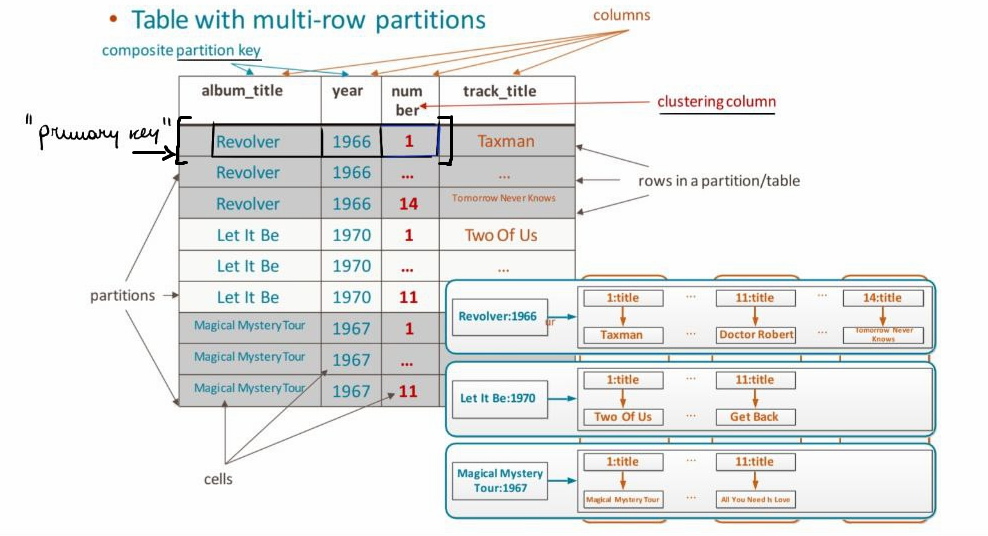
Collection columns are multi-valued columns (set, list, map). They cannot be part of a primary key, a partition key, cannot be used as clustering column and cannot be nested inside of another collection.
The table does not physically exist, but we need it for the queries.
2.7 CQL
A keyspace is a top-level namespace for a CQL table schema, it defines the replication strategy for a set of tables. Data objects (e.g., tables) belong to a single keyspace.
2.7.1 Keyspace Operations
To create a keyspace:
CREATE KEYSPACE musicdb
WITH replication = { 'class':
'SimpleStrategy',
'replication_factor' : 3
};To assign the working default keyspace for a cqlsh session:
USE musicdb;To delete a keyspace and all internal data objects:
DROP KEYSPACE musicdb;2.7.2 Table Operations
To create a table in the current keyspace:
Primary key declared inline:
CREATE TABLE performer (
name VARCHAR PRIMARY KEY,
type VARCHAR,
country VARCHAR,
style VARCHAR,
founded INT,
born INT,
died INT
);Primary key declared in separate clause:
CREATE TABLE performer (
name VARCHAR,
type VARCHAR,
country VARCHAR,
style VARCHAR,
founded INT,
born INT,
died INT,
PRIMARY KEY (name)
);We can define the primary key in different ways:
Simple partition key, no clustering columns:
PRIMARY KEY ( partition_key_column )Composite partition key, no clustering columns:
PRIMARY KEY ( ( partition_key_col1, ..., partition_key_colN ) )Simple partition key and clustering columns:
PRIMARY KEY ( partition_key_column, clustering_column1, ..., clustering_columnM )Composite partition key and clustering columns:
PRIMARY KEY ( ( partition_key_col1, ..., partition_key_colN ), clustering_column1, ..., clustering_columnM )
2.7.3 Altering and Dropping Tables
ALTER TABLE manipulates the table metadata.
Adding a column:
ALTER TABLE album ADD cover_image VARCHAR;Changing a column data type:
ALTER TABLE album ALTER cover_image TYPE BLOB;- Types must be compatible
- Clustering and indexed columns are not supported
Dropping a column:
ALTER TABLE album DROP cover_image;- PRIMARY KEY columns are not supported
DROP TABLE removes a table (all data in the table is lost):
DROP TABLE album;2.7.4 Distributed Counters
Cassandra supports distributed counters, which are useful for tracking a count.
- Counter column stores a number that can only be updated (incremented or decremented)
- Cannot assign an initial value to a counter (initial value is 0)
- Counter column cannot be part of a primary key
- If a table has a counter column, all non-counter columns must be part of a primary key
CREATE TABLE ratings_by_track (
album_title VARCHAR,
album_year INT,
track_title VARCHAR,
num_ratings COUNTER,
sum_ratings COUNTER,
PRIMARY KEY (album_title, album_year, track_title)
);Performance considerations:
- Read is as efficient as for non-counter columns
- Update is fast but slightly slower than an update for non-counter columns (a read is required before a write can be performed)
Accuracy considerations:
- If a counter update is timed out, a client application cannot simply retry a “failed” counter update as the timed-out update may have been persisted
- Counter update is not an idempotent operation
- Running an increment twice is not the same as running it once
2.7.5 Clustering Order
CLUSTERING ORDER BY defines how data values in clustering columns are ordered (ASC or DESC) in a table.
- ASC is the default order for all clustering columns
- When retrieving data, the default order or the order specified by a
CLUSTERING ORDER BYclause is used - The order can be reversed in a query using the
ORDER BYclause
CREATE TABLE albums_by_genre (
genre VARCHAR,
performer VARCHAR,
year INT,
title VARCHAR,
PRIMARY KEY (genre, performer, year, title)
) WITH CLUSTERING ORDER BY
(performer ASC, year DESC, title ASC);2.7.6 Secondary Indexes
Tables are indexed on columns in a primary key.
- Search on a partition key is very efficient
- Search on a partition key and clustering columns is very efficient
- Search on other columns is not supported
Secondary indexes can index additional columns to enable searching by those columns.
- One column per index
- Cannot be created for counter columns or static columns
To create a secondary index:
CREATE INDEX performer_style_key ON performer (style);To drop a secondary index:
DROP INDEX performer_style_key;When to use:
- With low-cardinality columns (columns that may contain a relatively small set of distinct values, e.g., music styles)
- With smaller datasets or when prototyping
Do not use:
- On high-cardinality columns
- On counter column tables
- On frequently updated or deleted columns
- To look for a row in a large partition unless narrowly queried (e.g., search on both a partition key and an indexed column)
2.7.7 Updating Data
UPDATE updates columns in an existing row.
UPDATE <keyspace>.<table>
SET column_name1 = value, column_name2 = value,
WHERE primary_key_column = value;- Row must be identified by values in primary key columns
- Primary key columns cannot be updated
- An existing value is replaced with a new value
- A new value is added if a value for a column did not exist before
Atomicity and isolation:
- Updates are atomic: all values of a row are updated or none
- Updates are isolated: two updates with the same values in primary key columns will not interfere (executed one after another)
2.7.8 Deleting Data
DELETE deletes a partition, a row, or specified columns in a row.
- Row must be identified by values in primary key columns
- Primary key columns cannot be deleted without deleting the whole row
To delete a partition from a table:
DELETE FROM track_ratings_by_user
WHERE user = 52b11d6d-16e2-4ee2-b2a9-5ef1e9589328;To delete a row from a table:
DELETE FROM track_ratings_by_user
WHERE user = 52b11d6d-16e2-4ee2-b2a9-5ef1e9589328 AND
activity = dbf3fbfc-9fe4-11e3-8d05-425861b86ab6;To delete a column from a table row:
DELETE rating FROM track_ratings_by_user
WHERE user = 52b11d6d-16e2-4ee2-b2a9-5ef1e9589328 AND
activity = dbf3fbfc-9fe4-11e3-8d05-425861b86ab6;2.7.9 Truncating Tables
TRUNCATE removes all rows in a table. The table definition (schema) is not affected.
TRUNCATE track_ratings_by_user;